
Integration Overview: Cribl
Integration Overview
The GreyNoise integration with Cribl is designed to help provide an enrichment source within Cribl that can be used in a data pipeline, so that events can be routed based on enriched data provided through the integration
Methods
Two different methods can be used to support an integration between GreyNoise and Cribl.
- Method 1: Using a Redis enrichment service
- Pros: Allows for extended context of GreyNoise data to be provided for each IP.
- Cons: Requires the extra infrastructure of building and supporting a Redis environment.
- Method 2: Using a binary lookup file
- Pros: Allows for in-memory binary file lookups with no extra infrastructure.
- Cons: Provides limited data fields for each enriched IP.
Method 1: Leveraging Redis
Prerequisites
- A GreyNoise API key with a paid subscription
- Cribl Stream
- A Redis environment that can be used to store the enrichment data
- An external system that can be used to connect to the GreyNoise API and add data to the Redis environment
Workflow
- The following outlines the data flow for this integration:
- A worker system uses a script to connect to the GreyNoise API to download the appropriate enrichment data. This download can be set to any cadence based on the freshness of the GreyNoise data desired, and can be based on any supported query for the GreyNoise GNQL API.
- Once the script pulls the data, it will then pass it to a Redis environment, using the IP as the key and the JSON response as the value stored in the Redis environment
- Within a Cribl stream pipeline, a Redis function is defined to connect to the Redis environment and to match the incoming events to the key values in the Redis dataset
- The enriched data is stored on the event and can be parsed out to allow for processing later in the pipeline
Installation Process
Redis Environment
If a Redis Environment does not exist, the following provides a simple guide to converting an Amazon EC2 instance to perform this function. Note that this is one of many ways to accomplish this step, and GreyNoise and Cribl can discuss the overall architecture as needed.
-
Create a new EC2 instance in the same region as your Cribl Cloud environment. This can be located within Cribl by clicking the
infoicon on the bottom left corner of the Cribl Cloud console: -
Set the EC2 instance to an instance size of
t2.mediumor equivalent instance, provide it with enough disk space to support the Redis environment. A size of 25G or more should be sufficient for basic functionality. -
Ensure the instance has a public IP. An Elastic IP is recommended to ensure the IP address remains even if the system is rebooted.
-
For the security groups, ensure that you allow SSH access for the system and inbound connections to port 6379 (the Redis default port). If desired, this can be modified to use a non-standard port.
-
Follow the basic installation instructions for Redis, setting it up to be available on the desired port and with appropriate authentication. You can follow the instructions provided by Redis HERE.
GreyNoise Script to Populate Redis
Once Redis is available (either by the steps above or via another method), the next step is to set up a regular task to query the GreyNoise API and populate the response into Redis.
The following script is an example of how to accomplish this. It uses the GreyNoise GNQL Metadata endpoint to pull data from one or more GNQL queries, format it, and insert it into Redis. The script uses multi-threading to increase performance and allow multiple queries to insert data into Redis simultaneously. By default, the following queries are included:
classification:benign last_seen:1dclassification:malicious last_seen:1dclassification:suspicious last_seen:1d
These default queries allow for all IPs seen by GreyNoise in the last day that do not have an unknown classification to be pushed into Redis.
The indicators are stored in Redis as a STRING entry that uses the IP as the key, and the API response for the API as the value in JSON format. This can later be parsed in Cribl.
Before running the script, make sure the necessary environment variables are set. These include the GreyNoise API key, Redis password, host, and port.
import json
import logging
import os
import sys
from concurrent.futures import ThreadPoolExecutor, as_completed
from typing import Dict
import redis
from greynoise.api import APIConfig, GreyNoise
GREYNOISE_API_KEY = os.getenv("GREYNOISE_API_KEY")
REDIS_PASSWORD = os.getenv("REDIS_PASSWORD", "")
REDIS_HOST = os.getenv("REDIS_HOST", "localhost")
REDIS_PORT = os.getenv("REDIS_PORT", 6379)
REDIS_KEY_EXPIRATION_SECONDS = os.getenv("REDIS_KEY_EXPIRATION_SECONDS", 604800)
# Configure logging
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(threadName)s - %(levelname)s - %(message)s",
)
LOGGER = logging.getLogger(__name__)
def setup_greynoise_session():
"""Initialize and return a GreyNoise session with error handling."""
try:
if not GREYNOISE_API_KEY:
LOGGER.error("GREYNOISE_API_KEY environment variable not set")
exit(1)
api_config = APIConfig(
api_key=GREYNOISE_API_KEY, integration_name="greynoise-to-redis-v2.0"
)
session = GreyNoise(api_config)
return session
except Exception as e:
LOGGER.error(f"Failed to initialize GreyNoise session: {e}")
exit(1)
def setup_redis_connection():
LOGGER.info("Creating redis connection")
try:
r = redis.Redis(
host=REDIS_HOST,
port=REDIS_PORT,
password=REDIS_PASSWORD,
)
# test connection to ensure redis is accessible, exit if not
r.set(
"127.0.0.1",
"testing",
ex=int(REDIS_KEY_EXPIRATION_SECONDS),
)
LOGGER.info("Redis is connected successfully")
return r
except ConnectionError as conne:
LOGGER.error("Unable to connect to redis: %s" % (conne))
sys.exit(1)
except Exception as e:
LOGGER.error(f"Unexpected error connecting to redis: {e}")
sys.exit(1)
def process_query(session: GreyNoise, r: redis.Redis, query: str) -> Dict[str, any]:
"""Process a single query and return results with error information."""
result = {
"query": query,
"success": False,
"error": None,
"ip_count": 0,
}
LOGGER.info(f"Starting to process query: {query}")
try:
LOGGER.info(f"Querying GreyNoise API for: {query}")
# Initial query
response = session.query(query=query, exclude_raw=True, size=10000)
# Check if response is valid
if not response or "request_metadata" not in response:
result["error"] = "Invalid response from GreyNoise API"
return result
count = response["request_metadata"].get("count", 0)
data = response.get("data", [])
if count == 0 or len(data) == 0:
LOGGER.warning(f"No data returned for query: {query}")
result["success"] = True # This is not an error, just no data
return result
LOGGER.info(f"Processing {count} IPs for query: {query}")
# Process first page
try:
for item in data:
json_data = json.dumps(item)
LOGGER.debug(f"Writing IP {item['ip']} to Redis")
r.set(
item["ip"],
str(json_data),
ex=int(REDIS_KEY_EXPIRATION_SECONDS),
)
result["ip_count"] += 1
except Exception as e:
LOGGER.error(f"Error adding data to redis: {e}")
raise e
# Process subsequent pages
scroll = response["request_metadata"].get("scroll")
complete = response["request_metadata"].get("complete", True)
while scroll and not complete:
LOGGER.info(f"Fetching next page for query: {query}")
try:
response = session.query(
query=query, scroll=scroll, exclude_raw=True, size=10000
)
if not response or "data" not in response:
LOGGER.warning(f"Invalid response for scroll query: {query}")
break
data = response["data"]
for item in data:
json_data = json.dumps(item)
LOGGER.debug(f"Writing IP {item['ip']} to Redis (scroll)")
r.set(
item["ip"],
str(json_data),
ex=int(REDIS_KEY_EXPIRATION_SECONDS),
)
result["ip_count"] += 1
LOGGER.debug(
f"Successfully wrote IP {item['ip']} to Redis (scroll)"
)
scroll = response["request_metadata"].get("scroll", "")
complete = response["request_metadata"].get("complete", True)
except Exception as e:
LOGGER.error(f"Error during scroll query for {query}: {e}")
break
result["success"] = True
LOGGER.info(
f"Successfully processed {result['ip_count']} IPs for query: {query}"
)
except Exception as e:
error_msg = f"Error processing query '{query}': {e}"
LOGGER.error(error_msg)
result["error"] = error_msg
return result
def main():
"""Main function to process all queries concurrently."""
queries = [
"classification:benign last_seen:1d",
"classification:malicious last_seen:1d",
"classification:suspicious last_seen:1d",
]
LOGGER.info(f"Starting processing of {len(queries)} queries with threading")
session = setup_greynoise_session()
r = setup_redis_connection()
# Process queries concurrently using ThreadPoolExecutor
with ThreadPoolExecutor(
max_workers=len(queries), thread_name_prefix="QueryWorker"
) as executor:
# Submit all queries
future_to_query = {
executor.submit(process_query, session, r, query): query
for query in queries
}
# Collect results as they complete
results = []
for future in as_completed(future_to_query):
query = future_to_query[future]
try:
result = future.result()
results.append(result)
if result["success"]:
LOGGER.info(
f"Query '{query}' completed successfully with {result['ip_count']} IPs"
)
else:
LOGGER.error(f"Query '{query}' failed: {result['error']}")
except Exception as e:
LOGGER.error(f"Unexpected error processing query '{query}': {e}")
results.append(
{
"query": query,
"success": False,
"error": f"Unexpected error: {e}",
"ip_count": 0,
}
)
# Summary
successful_queries = [r for r in results if r["success"]]
failed_queries = [r for r in results if not r["success"]]
total_ips = sum(r["ip_count"] for r in results)
LOGGER.info("=" * 50)
LOGGER.info("PROCESSING SUMMARY")
LOGGER.info("=" * 50)
LOGGER.info(f"Total queries processed: {len(results)}")
LOGGER.info(f"Successful queries: {len(successful_queries)}")
LOGGER.info(f"Failed queries: {len(failed_queries)}")
LOGGER.info(f"Total IPs processed: {total_ips}")
if failed_queries:
LOGGER.error("Failed queries:")
for result in failed_queries:
LOGGER.error(f" - {result['query']}: {result['error']}")
LOGGER.info("Processing complete!")
if __name__ == "__main__":
main()
Cribl Pipeline Updates
The idea behind this workflow is that the Redis lookup can be integrated into existing pipelines to include GreyNoise data in the processed events or serve as an additional parser to filter out events from the stream.
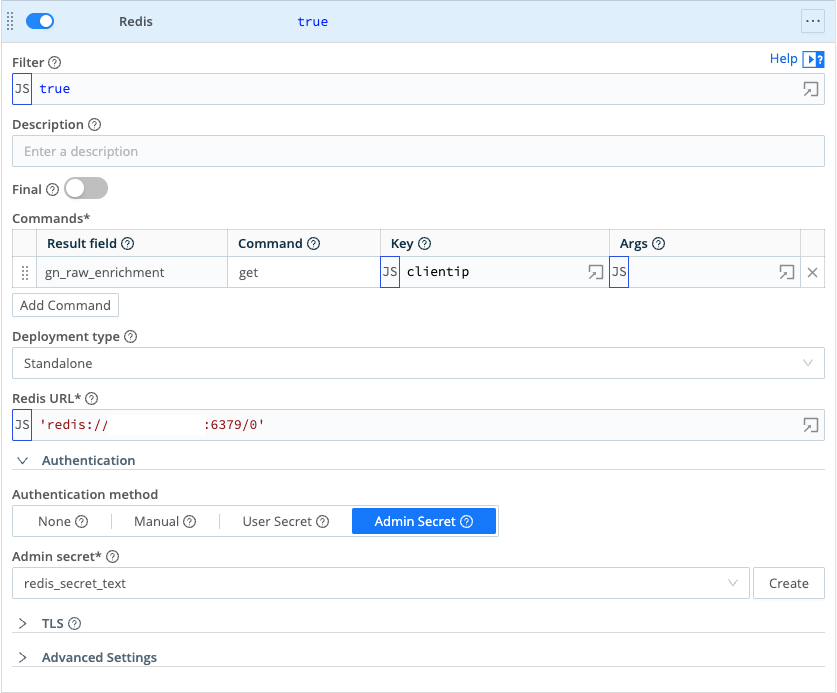
To implement this, add a Redis function to the pipeline. The following is an example that matches the "clientip" key in the source event with the Redis key and populates the IP data into a gn_raw_enrichment key.
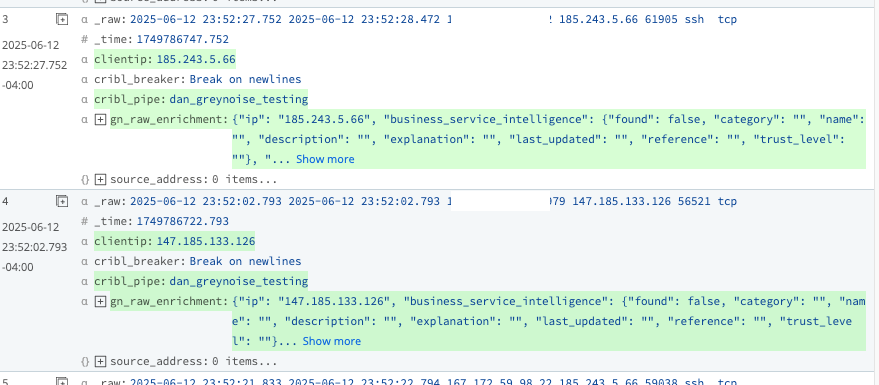
Here is a sample of the result of this initial step:
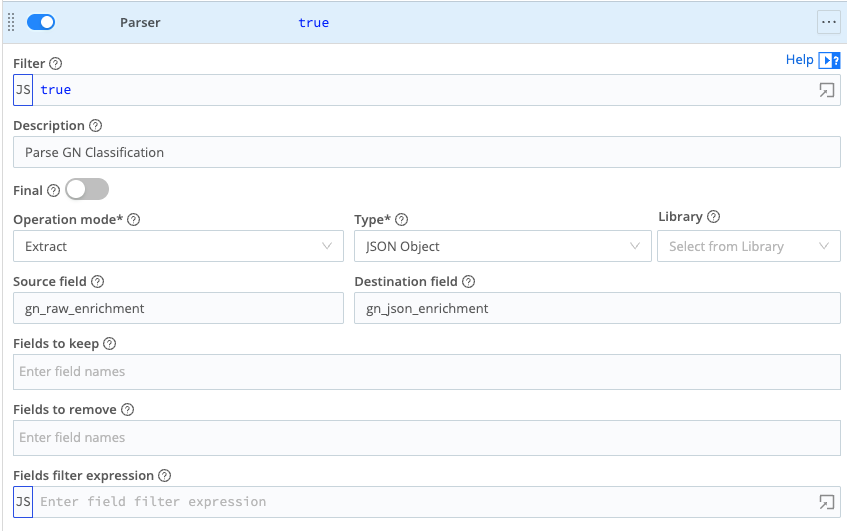
Next, add a Parse to convert the raw_data string into an accessible JSON format. In this example, the formatted JSON is stored in the gn_json_enrichment key:
Here is what the event looks like after this step:
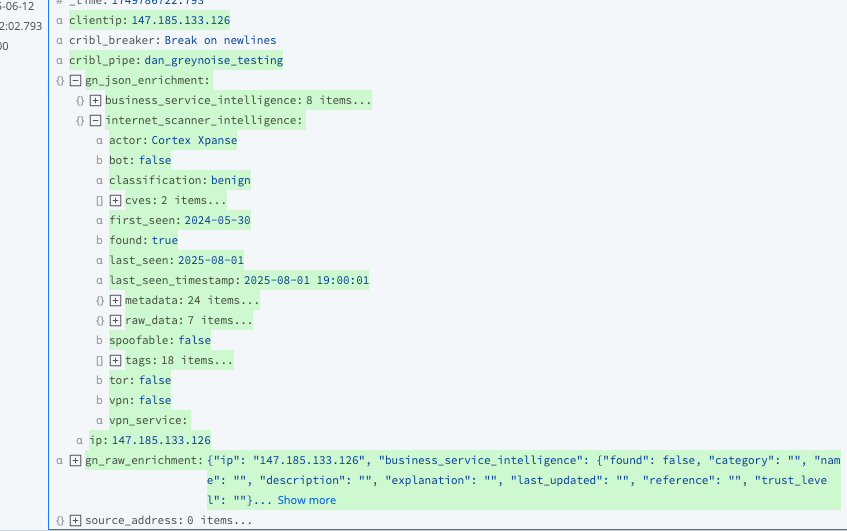
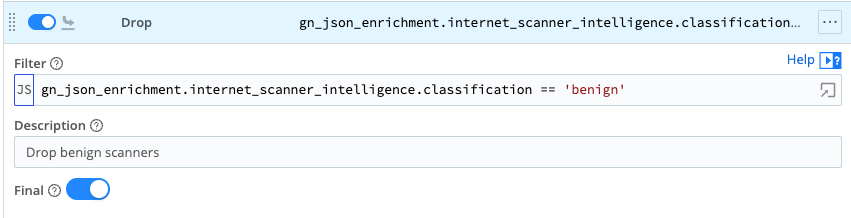
At this stage, the JSON data can simply be sent along with the event to the destination so it includes the enrichment data, or it can be used to filter or drop events based on the metadata. The following drop action uses the "classification" field to remove all "benign" IPs from the stream.
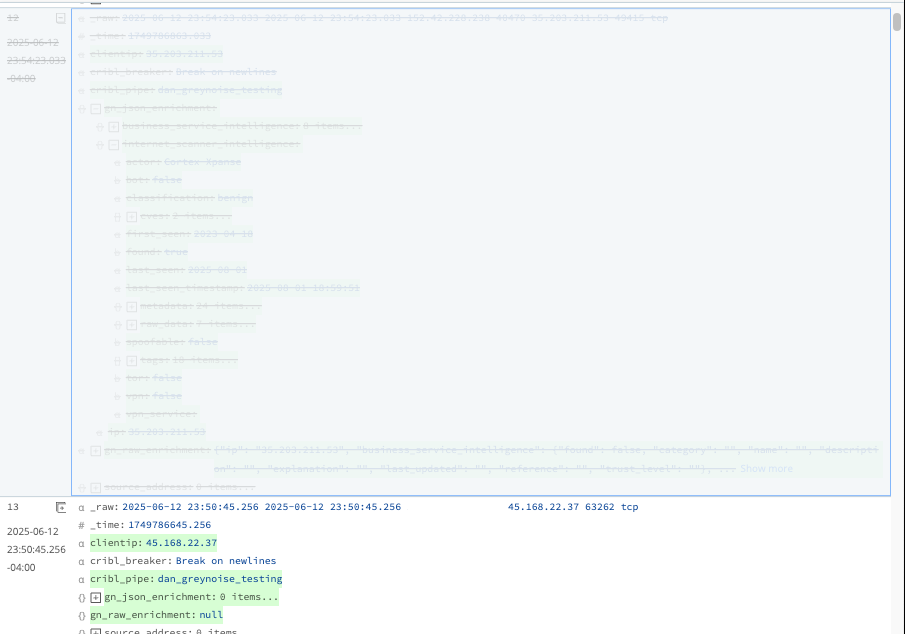
Stream is now dropping these events:
Method 2: Leveraging Binary Lookup File
Prerequisites
- A GreyNoise API key with a paid subscription
- Cribl Stream
- An external system that can be used to connect to the GreyNoise API and add data to Cribl via the Cribl API
Workflow
- The following outlines the data flow for this integration:
- A worker system uses a script to connect to the GreyNoise API to download the appropriate enrichment data. This download can be set to any cadence based on the freshness of the GreyNoise data desired, and can be based on any supported query for the GreyNoise GNQL API.
- Once the script pulls the data, it will push it to Cribl via the Cribl API.
- Within a Cribl stream pipeline, a GeoIP Lookup function is defined to leverage the lookup file and to match the incoming events to the key values in the lookup file.
- The enriched data is stored on the event and can be parsed out to allow for processing later in the pipeline
Installation Process
GreyNoise Script to send lookup file to Cribl
The following GitHub repo contains the information to set up and execute the script.
https://github.com/GreyNoise-Intelligence/greynoise-cribl-mmdb
When setting up the script, ensure that the appropriate.env file is created with the necessary API credentials and information, and the script is set to execute at a regular cadence (at least once per day, no more than once per hour).
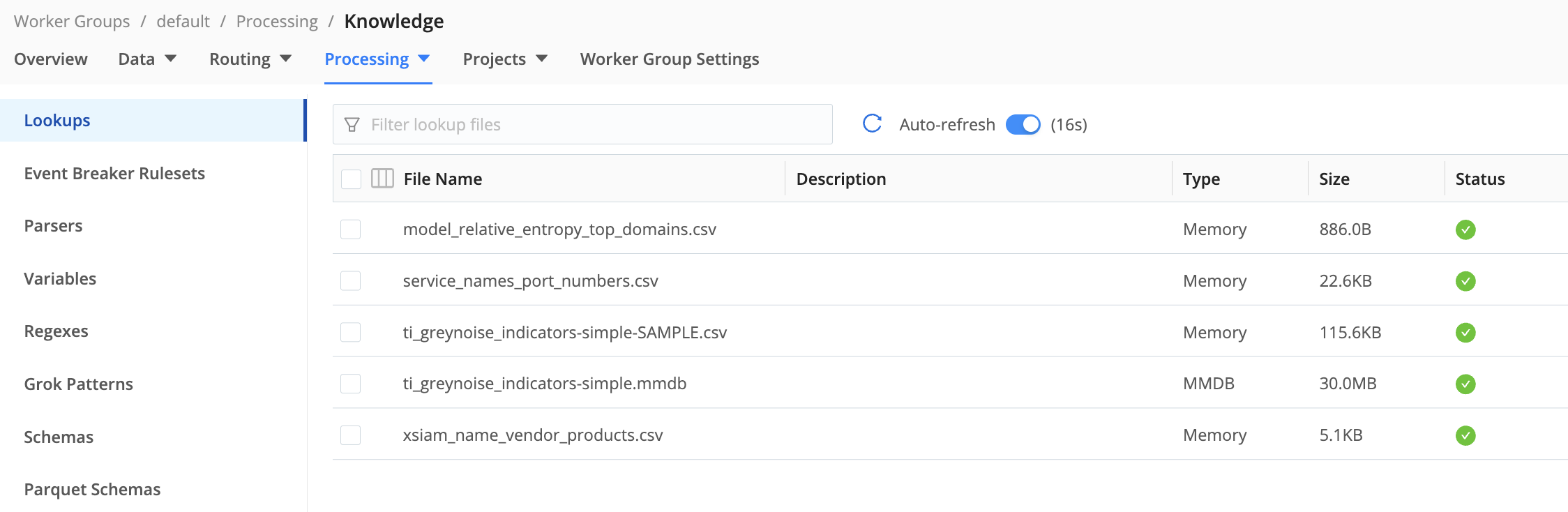
When successful, the lookup files will be visible in the Cribl Stream console under Processing -> Knowledge -> Lookups (file name(s) ti_greynoise_indicators-simple:
Cribl Pipeline Updates
The idea behind this workflow is that the file lookup can be integrated into existing pipelines to include GreyNoise data in the processed events or serve as an additional parser to filter out events from the stream.
To implement this, add a GeoIP function to the pipeline. The following is an example that matches the "src_ip" key in the source event with the lookup and populates the IP data into a gn_ip key.
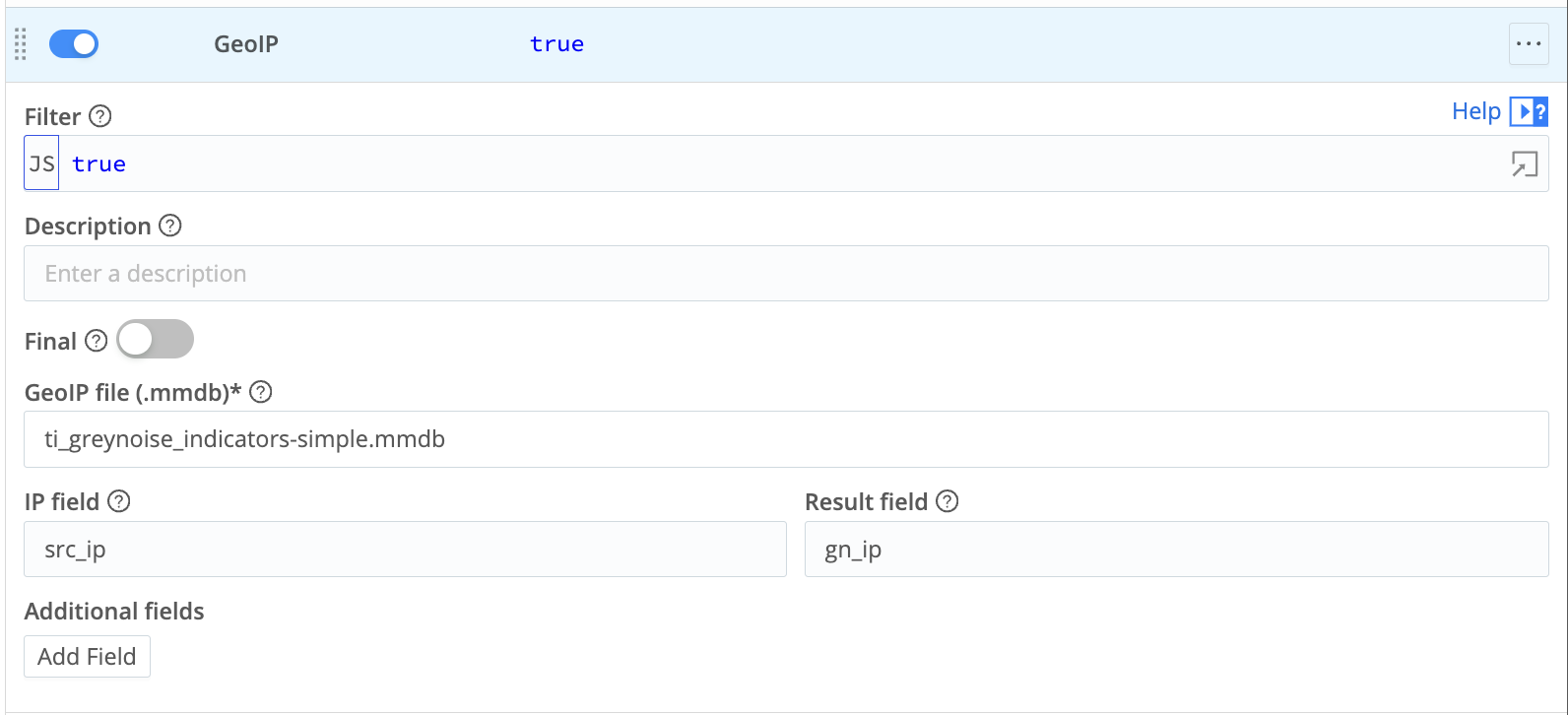
Here is a sample of the result of this initial step:

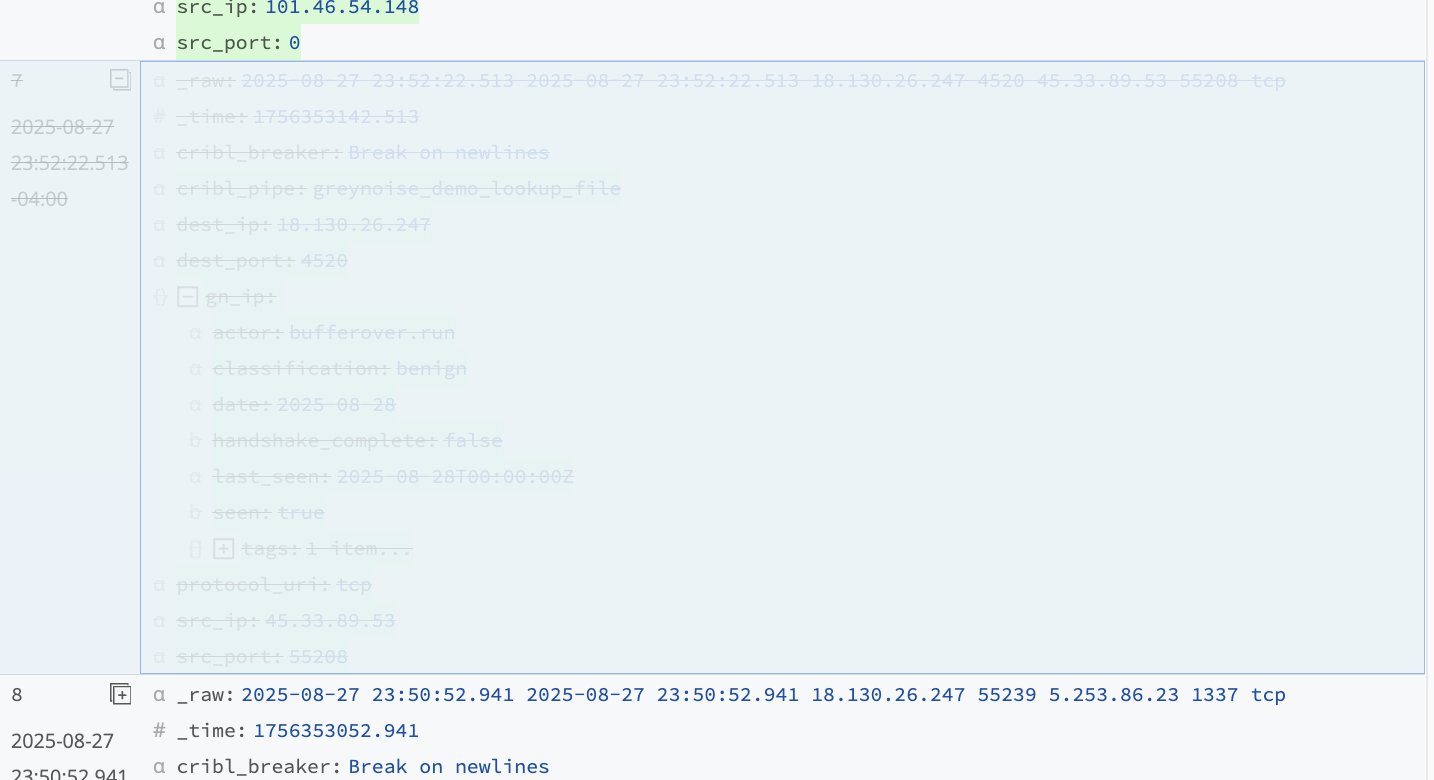
At this stage, the JSON data can be sent along with the event to the destination to include the enrichment data, or it can filter or drop events based on the metadata. The following drop action uses the "classification" field to remove all "benign" IPs from the stream.
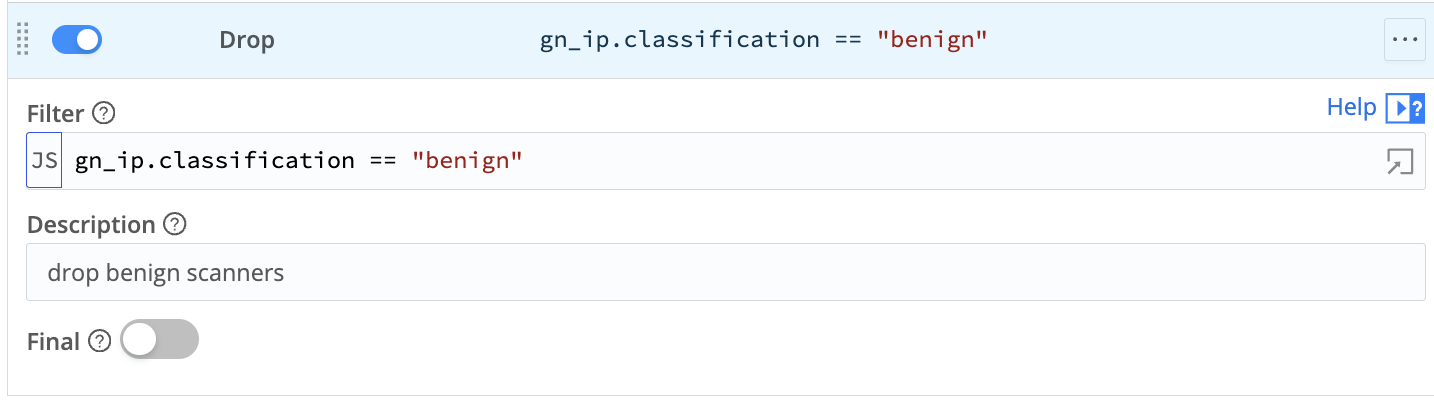
Stream is now dropping these events:
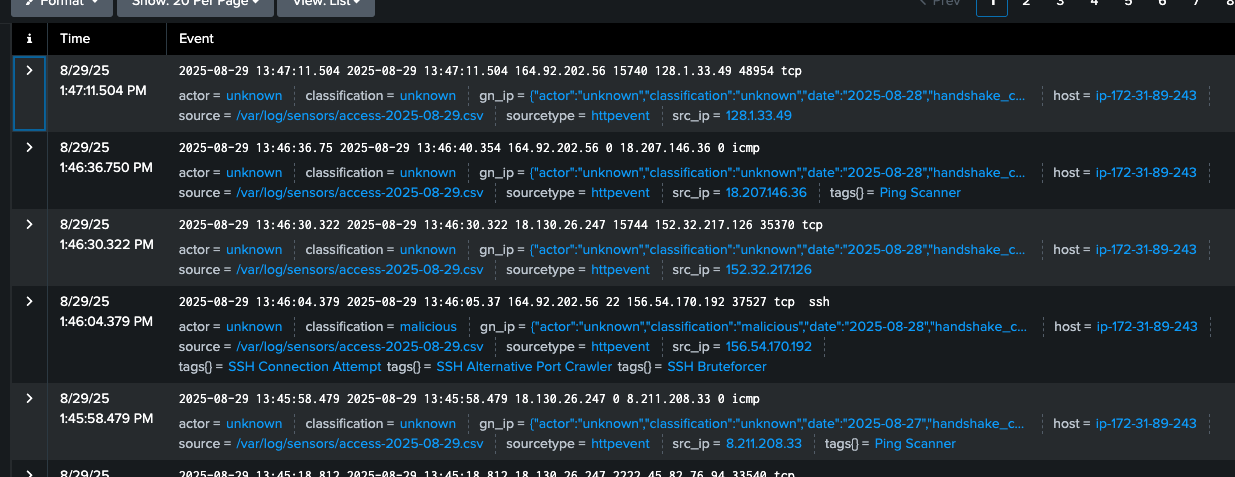
Final Result
The following is an example of a complete process flow that takes source event logs, processes, enriches, cleans, and then sends them to a final destination:
Updated 11 months ago